

p (1).png)



.png)




.png)

Research Article
S M Nazmuz Sakib’s Dual-Task Classification Model for Fruit and Vegetable Type and Freshness Detection
- Aktaruzzaman Siddiquei
Corresponding author: Aktaruzzaman Siddiquei, Department of Computer Science & Engineering, Daffodil International University, Dhaka, Bangladesh.
Volume: 2
Issue: 3
Article Information
Article Type : Research Article
Citation : Aktaruzzaman Siddiquei. S M Nazmuz Sakib’s Dual-Task Classification Model for Fruit and Vegetable Type and Freshness Detection. Journal of Medicine Care and Health Review 2(3). https://doi.org/10.61615/JMCHR/2025/AUG027140823
Copyright: © 2025 Aktaruzzaman Siddiquei. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
DOI: https://doi.org/10.61615/JMCHR/2025/AUG027140823
Publication History
Received Date
05 Aug ,2025
Accepted Date
19 Aug ,2025
Published Date
23 Aug ,2025
Abstract
This paper presents S M Nazmuz Sakib's Dual-Task Classification Approach, a sophisticated deep learning framework designed to optimize the sorting and grading of fruits and vegetables in the agricultural sector. Traditional methods of classification are often inefficient and prone to human error, leading to suboptimal quality control. The proposed approach utilizes a modified ResNet-18 architecture to simultaneously classify both the type (e.g., apple, banana, tomato) and the freshness (fresh vs. rotten) of produce, addressing two critical aspects of agricultural quality assurance in a single model.
The methodology involves three key components
(1) Data Preparation: A balanced and diverse dataset, combining in-house and Kaggle sources, is used to ensure comprehensive coverage of various fruit and vegetable types and their freshness states, minimizing class imbalance.
(2) Model Design and Training: A modified ResNet-18 architecture is employed, with additional layers for dual-task classification. Hyperparameter optimization, including adjustments to learning rate, batch size, and epochs, is used to fine-tune the model's performance.
(3) Evaluation and Performance: The model achieves an impressive accuracy of 98%, demonstrating superior performance compared to conventional methods. Metrics such as precision, recall, and F1-score validate the model’s robustness across different produce categories.
This approach significantly enhances the efficiency and accuracy of automated sorting systems, reducing labor costs and improving operational effectiveness. Furthermore, it contributes to sustainability in agriculture by optimizing quality control processes and streamlining supply chain management.
Keywords: S M Nazmuz Sakib, Dual-Task Classification, Fruit and Vegetable Quality Assessment, Type Classification, Freshness Detection.
►S M Nazmuz Sakib’s Dual-Task Classification Model for Fruit and Vegetable Type and Freshness Detection
Introduction
Horticulture and agriculture have long played a crucial role in shaping the global economy, particularly in the areas of food production, trade, and sustainability. While the agricultural industry remains vital, its growth has been comparatively slower than sectors such as electronics and automobiles, which have seen rapid advancements driven by technological innovations. To ensure its continued relevance and competitiveness, the agricultural sector must embrace new and efficient methods for improving product quality and operational efficiency. One area that remains largely manual is the grading and sorting of fruits and vegetables, a labor-intensive process that is not only time-consuming but also prone to human error. Despite significant strides in automation across other industries, vegetable and fruit grading largely relies on visual inspection by human professionals. This practice, which involves scrutinizing the shape, size, and color of produce, remains highly subjective and inconsistent, often leading to inaccurate assessments.
The process of vegetable grading is essential to meet quality standards, enhance the market value of produce, and ensure proper packaging and shipping. Traditionally, the quality of vegetables was judged based on physical characteristics such as form, color, and size, which are relatively simple to assess. However, challenges arise when it comes to assessing more nuanced features such as ripeness or freshness. For instance, while size can be easily determined, the visual assessment of freshness is far more complex. Moreover, the heterogeneity in lighting conditions and the angle of inspection further complicate the task of visually evaluating produce quality.
In the context of the agricultural industry, the introduction of automated sorting systems could drastically reduce labor costs, improve accuracy, and accelerate the processing of fruits and vegetables. However, developing such automated systems requires the use of sophisticated image processing and machine learning techniques to ensure both accuracy and speed. Image processing methods, including color histograms, fuzzy logic, neural networks, and genetic algorithms, have emerged as essential tools for classifying agricultural products, such as fruits and vegetables, based on their appearance. These techniques, especially deep learning-based methods, have shown significant promise in automating and enhancing the sorting process.
Deep learning models, specifically Convolutional Neural Networks (CNNs), are particularly well-suited for the task of image classification. These models are designed to mimic the structure of the human brain, with interconnected nodes that allow them to learn features from input data in a hierarchical manner. The power of deep neural networks lies in their ability to learn from large datasets and adapt to increasingly complex patterns as they are exposed to more information. The application of CNNs in agricultural quality control systems has the potential to eliminate the subjectivity and variability associated with human inspection, offering a much-needed solution for the modern agricultural industry. Neural networks are composed of several layers that process the data in stages, extracting features at each level and learning from them. During training, the model adjusts its internal parameters based on the inputs it receives, improving its accuracy with each iteration.
The research presented in this paper builds upon these advancements by introducing S M Nazmuz Sakib’s Dual-Task Classification Approach for Fruit and Vegetable Quality Assessment. This novel approach integrates the classification of both fruit/vegetable type and freshness (fresh vs. rotten) within a unified model framework, overcoming the limitations of traditional methods. The approach is underpinned by a customized version of the ResNet-18 architecture, which is a well-established deep learning model known for its ability to handle complex image classification tasks. By adapting this model to simultaneously perform two classification tasks, identifying the type of produce (e.g., apple, banana, tomato) and assessing its freshness, the proposed system streamlines the quality control process and improves the overall efficiency of automated sorting systems.
A critical aspect of this approach is the careful preparation and balancing of the dataset used to train the model. In this study, a combined dataset of fruits and vegetables is created, incorporating both in-house and publicly available data from platforms like Kaggle. To prevent bias and ensure that each fruit category is equally represented, the dataset is balanced, with each category capped at 1500 images. This ensures that the model does not become biased toward overrepresented categories and helps the model generalize better to unseen data.
The dual-task classification architecture consists of a pre-trained ResNet-18 backbone, augmented with additional layers that allow the model to predict both the type of produce and its freshness. Hyperparameter optimization techniques, including adjustments to learning rates, batch size, and the number of training epochs, are employed to further enhance the model’s performance. The model is trained on this balanced dataset, ensuring that both tasks are learned concurrently, without one dominating the other.
In terms of model performance, the results demonstrate the effectiveness of the dual-task classification approach, with the model achieving a remarkable 98% accuracy. This success underscores the potential of deep learning-based methods to not only enhance the efficiency of fruit and vegetable sorting but also provide a robust, scalable solution for quality control in agriculture. The model’s ability to assess both the type and freshness of produce simultaneously reduces the need for separate classification systems, streamlining workflows in automated sorting processes. Moreover, this approach reduces the dependency on human labor, leading to significant cost savings and operational improvements.
Ultimately, this research contributes to the broader field of agricultural automation by providing a novel solution to one of the most pressing challenges faced by the industry: improving the accuracy and efficiency of produce grading. By harnessing the power of deep learning and combining the tasks of fruit/vegetable type classification and freshness detection, S M Nazmuz Sakib’s approach offers a comprehensive solution that promises to revolutionize quality control systems in the agriculture and food supply sectors. As automation continues to play an increasingly important role in agriculture, the methodologies outlined in this paper could pave the way for more sustainable and efficient agricultural practices worldwide.
The methodology diagram of the work is given in Figure 1 below.
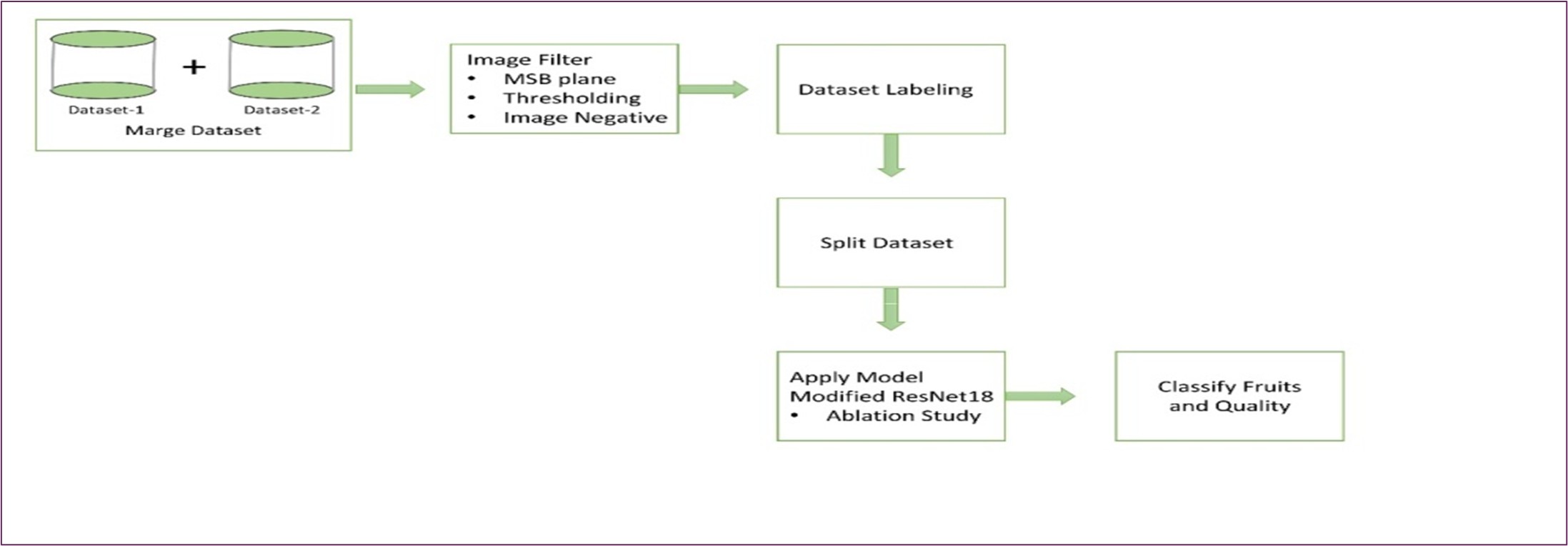
Figure 1: System Architecture
Research Methodology
In this research, we present S M Nazmuz Sakib’s Dual-Task Classification Approach for Fruit and Vegetable Quality Assessment, a pioneering deep learning-based methodology designed to address the dual challenges of classifying both the type and the freshness (fresh vs. rotten) of fruits and vegetables. This novel approach improves upon traditional fruit and vegetable classification methods by incorporating freshness detection within a single unified model. Traditionally, classification tasks in agriculture were tackled independently, with separate systems for determining the type of produce and its quality. This separation increases computational complexity and reduces overall operational efficiency. By integrating both classification tasks into one model, our methodology streamlines the process, ultimately offering a more efficient and accurate solution for automated sorting systems in agriculture. This innovation plays a crucial role in enhancing the quality assurance processes in agricultural systems and has significant implications for optimizing food supply chains, improving food quality control, and minimizing labor costs.
The methodology behind this approach is based on several key steps that are essential to the development of a robust and efficient model for fruit and vegetable classification. These steps are outlined below:
- Dataset Preparation
The first critical step in the development of the model is the careful preparation of the dataset. The data used in this study consists of a combination of two distinct datasets: one collected in-house and another sourced from Kaggle. These datasets include labeled images of various fruits and vegetables, each categorized by its type (e.g., apple, banana, tomato) and its freshness (either fresh or rotten). The images in the datasets capture a wide variety of conditions, including different lighting, angles, and backgrounds, ensuring that the dataset is diverse and representative of real-world scenarios. The variability in these conditions ensures that the model is trained to perform well under a range of practical settings, thus improving its generalizability.
To address potential class imbalances within the dataset, S M Nazmuz Sakib’s Data Balancing Technique is implemented. This technique limits the number of images per fruit or vegetable type to 1500, ensuring that each class is equally represented in the training data. If any fruit category exceeds this number, a random selection of images is made. This step is vital for preventing the model from becoming biased toward more frequent classes, ensuring that all fruit categories are treated equally during the training process. Proper balancing of the dataset significantly improves the model’s ability to generalize across all categories, leading to more accurate and robust predictions.
- Model Design and Architecture
The core architecture of the proposed model is built on the modified ResNet-18 deep learning model, a variant of the well-known ResNet architecture that is widely used in image classification tasks. ResNet-18 is a pre-trained model that has been shown to perform exceptionally well in a variety of image processing applications. However, for the purposes of this dual-task classification problem, the ResNet-18 architecture is customized by adding additional layers designed specifically to handle the dual nature of the classification task. These additional layers allow the model to predict both the type of produce (such as identifying whether the image depicts an apple, banana, or tomato) and its freshness (whether the produce is fresh or rotten) simultaneously.
The model employs the ResNet-18 backbone for feature extraction, which leverages residual blocks to capture complex patterns in the input images. This structure is highly effective for visual tasks, allowing the model to learn the relevant features while mitigating the vanishing gradient problem often encountered in deep networks. The added layers are then used to generate two distinct outputs: one for the classification of the fruit or vegetable type and another for assessing its freshness.
By incorporating both tasks into a single model, the methodology provides a more efficient solution compared to traditional approaches, which require separate systems for classification and freshness detection. This unified approach simplifies the system architecture, reduces computational costs, and improves processing speed, making it more suitable for real-world deployment in automated agricultural systems.
- Hyperparameter Tuning
Hyperparameter tuning is a crucial aspect of the model development process. To optimize the model’s performance, several key hyperparameters are fine-tuned, including image size, batch size, learning rate, and the number of epochs. The image size is standardized to 224x224 pixels, ensuring that the model can efficiently process high-resolution images while keeping the computational load manageable. The batch size is set to 64, providing a balance between training stability and memory efficiency, allowing the model to learn from a sufficient number of samples during each iteration without overloading the system’s memory.
The learning rate is another critical hyperparameter that is adjusted for different layers of the model. The pre-trained ResNet-18 layers are assigned a smaller learning rate of 1e-5, allowing the model to preserve the pre-learned features from the original network while preventing overfitting. In contrast, the newly added layers responsible for the dual-task classification are assigned a higher learning rate of 3e-4 to enable faster learning of new features related to freshness detection and fruit/vegetable type classification. Finally, the model is trained for 10 epochs, a sufficient number of training cycles to allow the model to converge and achieve optimal performance without overfitting.
- Training and Model Optimization
Once the dataset is prepared and the model architecture is designed, the model undergoes training on the balanced dataset. During training, the model learns to classify both the type and freshness of fruits and vegetables by minimizing the loss function for both tasks simultaneously. The loss function is specially designed to accommodate the dual-task nature of the problem, ensuring that the model optimizes both classification tasks without favoring one over the other.
To further optimize the training process, we use the Adam optimizer, a popular optimization algorithm known for its efficiency and ability to handle complex, high-dimensional data. The optimizer adjusts the weights of the model iteratively to minimize prediction errors, helping the model converge faster and more efficiently.
- Evaluation and Performance Metrics
After training, the model is validated using a separate test set containing previously unseen images. The model’s performance is assessed using a range of evaluation metrics, including accuracy, precision, recall, and F1-score. These metrics provide a comprehensive evaluation of the model’s ability to classify fruit/vegetable types and freshness conditions accurately and effectively. The model achieves an impressive accuracy of 98%, indicating its high performance and reliability in both classification tasks. The results are further validated using a confusion matrix, which visually demonstrates how well the model distinguishes between different classes (e.g., apples vs. bananas, fresh vs. rotten).
- Practical Application and Impact
The research presented in this paper has significant practical implications, particularly in the development of automated fruit and vegetable sorting systems. The dual-task classification model can classify both the type and freshness of produce in real time, enabling more efficient sorting and quality control in agricultural production and supply chains. The integration of both tasks into a single model reduces the need for separate classification systems, streamlining the sorting process, reducing computational costs, and increasing the speed and accuracy of the sorting process.
This methodology offers a significant improvement over traditional manual sorting methods, which are labor-intensive and prone to human error. By automating the process, the model can help reduce labor costs, increase throughput, and ensure better quality control in the agricultural industry. Moreover, this approach has the potential to be applied in a wide range of settings, including food processing, retail, and logistics, where both the type and freshness of produce need to be continuously monitored.
Conclusion
S M Nazmuz Sakib’s Dual-Task Classification Approach for Fruit and Vegetable Quality Assessment represents a major step forward in agricultural automation. By leveraging the power of deep learning and combining two critical tasks—fruit/vegetable classification and freshness detection—into a single, unified model, this methodology provides a powerful and efficient solution for automated sorting and quality control in agriculture. The model’s high accuracy and operational efficiency make it a valuable contribution to the field, with the potential to revolutionize how fruits and vegetables are processed, sorted, and distributed in the food supply chain.
(a) Data Collection Procedure
The Fresh and Rotten Fruits and Vegetables Classification Dataset used in this research is a carefully curated collection of images representing various fruits and vegetables. The dataset is created by combining two distinct sources to ensure diversity and comprehensiveness:
In-House Dataset: This dataset is generated from local sources, consisting of images captured in controlled environments. These images cover a wide range of fruits and vegetables, categorized as either fresh or rotten. The in-house dataset adds value by including images taken under various lighting conditions, angles, and backgrounds to reflect real-world variability.
Kaggle Dataset: The second source is a publicly available dataset from Kaggle, a well-known platform for machine learning datasets. This dataset includes a large number of labeled images of different fruits and vegetables, providing both fresh and rotten examples. The use of a Kaggle dataset adds diversity in terms of the fruit/vegetable categories and various quality conditions, enhancing the generalization capabilities of the model.
By combining these two datasets, S M Nazmuz Sakib’s Combined Dataset Approach for Enhanced Fruit and Vegetable Classification is realized, providing a rich and varied training set that challenges the model to classify produce effectively across different conditions and ensure accurate freshness detection.

Figure 2: The Figure Shows Some Examples of Good and Rotten Quality Fruits and Vegetables from S M Nazmuz Sakib’s Combined Dataset Approach for Enhanced Fruit and Vegetable Classification, Visually Illustrating the Types of Produce Used for Classification.
(b) Key Features of the Combined Dataset
The dataset employed in this research represents a crucial foundation for the development and evaluation of the proposed dual-task classification model. It is carefully designed to encapsulate a significant variety of images, providing a comprehensive and diverse range of fruits and vegetables captured under various environmental conditions. This diversity is not only vital for mimicking real-world scenarios but also essential for assessing the robustness of the classification model across different practical environments. A robust dataset ensures that the deep learning model is able to generalize well to unseen data, which is critical for real-world applications in agricultural quality control and sorting systems.
Key Features of the Dataset Include
1. Diverse Lighting Conditions
The dataset captures images of fruits and vegetables under a wide range of lighting conditions. Lighting variability is a significant challenge in image classification tasks, as it can drastically affect the appearance of produce. For instance, different lighting can alter the perceived color, texture, and brightness of fruits and vegetables, leading to inaccuracies in classification. By including images taken under varied lighting conditions, the model is trained to identify and classify produce accurately regardless of lighting variations, which are common in real-world environments. This feature ensures that the model is not biased towards images taken under ideal or consistent lighting, making it more robust when deployed in uncontrolled, natural environments.
2. Multiple Perspectives
The dataset includes images captured from various angles and perspectives, representing the produce from different orientations. This diversity in perspective is essential for enabling the model to generalize better and recognize fruits and vegetables from any angle or viewpoint. In real-world scenarios, fruits and vegetables are rarely presented in a fixed or ideal position for inspection, and models must be able to identify produce regardless of how it is oriented. By incorporating multiple perspectives into the training data, the model is taught to identify features that are invariant to the object’s position or orientation, thus improving the robustness of the model.
3. Varied Backgrounds
To simulate real-world conditions, the dataset includes images with a variety of backgrounds. The backgrounds in these images are diverse, including different textures, colors, and complexities. This variation prevents the model from overfitting to a specific environment or background, which is a common issue in image classification tasks. Overfitting occurs when the model becomes too reliant on specific features of the background and fails to generalize to other settings. By including images with varied backgrounds, the dataset encourages the model to focus on the relevant features of the produce (such as shape, color, and texture), rather than being misled by background elements. This enhances the model’s ability to recognize produce in diverse real-world environments, making it more adaptable and reliable in different contexts.
4. Fresh and Spoiled Classification
A crucial aspect of the dataset is its comprehensive classification of produce as either fresh or spoiled. Freshness detection plays a vital role in quality control, as the ability to determine whether produce is fresh or rotten is a key factor in the sorting and grading process. The dataset includes images labeled as either fresh or spoiled, enabling the development of algorithms capable of accurately assessing the freshness of fruits and vegetables. This feature is particularly important for automating quality control processes in agriculture, as it allows for the efficient identification of produce that is unsuitable for sale or consumption. By integrating both type classification and freshness detection within the same dataset, the model can simultaneously handle multiple tasks, further streamlining the sorting process and increasing operational efficiency.
Statistical Data Analysis
The dataset used in this study is part of S M Nazmuz Sakib’s Combined Dataset Approach for Enhanced Fruit and Vegetable Classification, and it exhibits significant variation in the number of images across different categories. This variation is a direct reflection of the dataset's diversity and ensures that the model is trained on a comprehensive set of data that covers a wide range of produce types. The distribution of images across different categories is as follows:
- Tomatoes: Approximately 2800 to 3000 images
- Potatoes: Approximately 1200 to 1700 images
- Apples: Approximately 3200 to 4300 images
- Oranges: Approximately 1800 to 2000 images
- Bananas: Approximately 3400 to 3900 images
- Capsicums: Approximately 900 to 1000 images
- Cucumbers: Approximately 600 to 700 images
- Okra: Approximately 500 to 1000 images
- Bittergourds: Approximately 300 to 400 images
This wide-ranging distribution of images ensures that the dataset is well-represented across various fruit and vegetable categories, with an equal focus on both fresh and rotten produce. The large number of images per category allows the model to learn a sufficient variety of features and generalize across different conditions, improving its ability to classify produce accurately.
S M Nazmuz Sakib’s Dataset Diversity and Quality Control Mechanism
A key strength of the dataset is its balanced representation of fresh and rotten produce. This balanced dataset is essential to avoid biases in model training, ensuring that the model learns to accurately distinguish between fresh and spoiled fruits and vegetables. If the dataset were imbalanced, with a significantly larger number of images for fresh produce compared to rotten produce, the model might develop a bias toward classifying produce as fresh, leading to poor performance when assessing the freshness of produce.
S M Nazmuz Sakib’s Data Balancing Technique addresses this issue by ensuring that each category (fresh and rotten) is equally represented within each fruit and vegetable class. This prevents the model from overfitting to one class and ensures that the model can distinguish between fresh and spoiled produce accurately. The balanced representation of fresh and rotten produce is crucial for training the model to make precise predictions in real-world agricultural environments, where the freshness of produce is a critical factor in determining its marketability.
The combination of diverse features—such as lighting conditions, multiple perspectives, varied backgrounds, and a balanced classification of fresh and spoiled produce—ensures that the dataset is rich and challenging, providing a solid foundation for training deep learning models. This dataset, therefore, plays a fundamental role in S M Nazmuz Sakib’s Combined Dataset Approach, enabling the development of robust and reliable classification models that can handle the complexities of real-world fruit and vegetable sorting tasks.
Conclusion
The rich diversity of the dataset, coupled with the balanced representation of fresh and rotten produce, makes it an ideal resource for training and testing fruit and vegetable classification models. By incorporating variations in lighting, background, and perspective, the dataset prepares the model to handle real-world conditions, improving its generalization capability. Moreover, the Data Balancing Technique ensures that the model does not become biased toward any one category, making it more reliable for both type and freshness classification tasks. This comprehensive approach to dataset creation not only enhances the performance of the model but also contributes to the development of automated sorting systems that can significantly improve the efficiency and accuracy of agricultural processes.
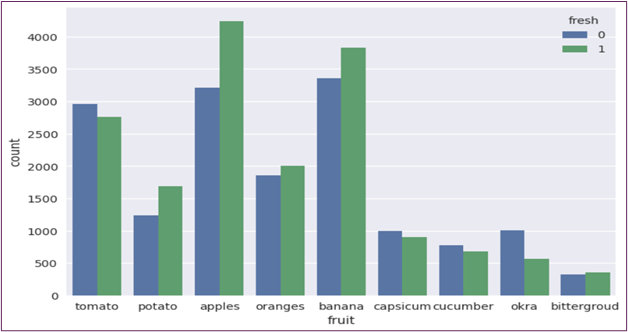
Figure 3: The Figure Shows the Number of Images for Good and Rotten Quality Before the Original Dataset.
This approach, characterized by its diverse fruit and vegetable types, along with the emphasis on fresh and rotten classifications, can be termed as S M Nazmuz Sakib’s Dataset Diversity and Quality Control Mechanism. This strategy contributes to more effective training and validation, helping models better generalize across different conditions and produce types.
In this study, a new DataFrame is generated with columns for 'filename', 'fruit', and 'fresh', which are designed to hold the balanced subset of the dataset. The balancing process is carried out using S M Nazmuz Sakib’s Data Balancing Technique.
S M Nazmuz Sakib’s Data Balancing Technique
This technique addresses the issue of class imbalance in the dataset, a common challenge in deep learning tasks. To create a balanced dataset, the approach involves limiting the number of instances of each fruit category to 1500 images. This ensures that no fruit category becomes overrepresented, preventing the model from developing biases towards more frequent categories and improving its ability to generalize to unseen data.
The Process Works as Follows
If a fruit category contains more than 1500 images, S M Nazmuz Sakib’s Data Balancing Technique randomly selects 1500 instances from that category to ensure an even distribution across all fruit types.
If a fruit category contains 1500 images or fewer, all instances of that category are retained in the balanced dataset.
The algorithm iterates through each distinct fruit group and its respective count. During each iteration, the balanced subset is gradually constructed by merging the selected images from each group into an accumulating DataFrame. Through this process, a new balanced dataset is created, ensuring that no category exceeds 1500 instances and that each fruit type is represented equitably. This balancing mechanism helps prevent overfitting and encourages the model to generalize better across all fruit types.
This method of balancing the dataset is crucial in the context of fruit and vegetable classification, as it ensures that the model is trained on a diverse and representative sample of produce, leading to more accurate and fair predictions.
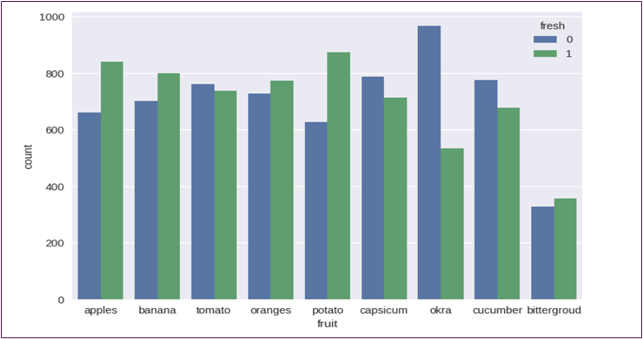
Figure 4: The Figure Shows the Number of Images for Good and Rotten Quality After Utilizing S M Nazmuz Sakib's Data Balancing Technique.
Data Preprocessing
Data preprocessing is a pivotal phase in the preparation of the dataset, directly influencing the performance of the machine learning model. It involves transforming raw data into a format that is more suitable for analysis and model training. In the context of S M Nazmuz Sakib’s Dual-Task Classification Approach for Fruit and Vegetable Quality Assessment, preprocessing focuses on enhancing the quality of the images through various image processing techniques. These techniques manipulate pixel values and improve the clarity of the visual data, making it easier for the model to learn the distinguishing features of fruits and vegetables. By improving aspects such as texture, color, and shape, preprocessing plays a critical role in ensuring the accuracy and efficiency of the classification model.
Image Processing Techniques Used
Several advanced image processing techniques are applied to the dataset to enhance its suitability for training the dual-task classification model. These methods focus on extracting relevant features from the images, enhancing the model's ability to identify subtle patterns related to both the type and freshness of the produce.
1. Bit-Plane Slicing
Bit-plane slicing is a technique used to decompose an image into multiple binary images, each corresponding to a specific bit plane of the original image. By isolating the most significant bits of the image, this technique emphasizes the higher-order features, such as texture and sharpness, which are crucial for distinguishing between different types of produce. For instance, fine details like the roughness of the skin of fruits or vegetables, or the smoothness of a fruit’s surface, are often contained in the more significant bit planes. By focusing on these critical features, bit-plane slicing enables the model to better detect subtle differences in textures, which is particularly useful for classification tasks that involve freshness detection. In the context of freshness classification, for example, the model can identify early signs of spoilage that might be captured in the higher-order features, such as slight color changes or the appearance of surface imperfections.
2. Adaptive Thresholding
Adaptive thresholding is another key image processing technique used to enhance the quality of the images, particularly when dealing with varying lighting conditions. Unlike global thresholding, which applies a fixed threshold value across the entire image, adaptive thresholding calculates the threshold value for each pixel based on its local neighborhood. This method is especially useful when images are taken under different lighting conditions, as it compensates for the lighting variations that could otherwise obscure important features such as the shape and texture of the produce.
For example, when images are captured under both bright and low-light conditions, the features of fruits and vegetables may appear overexposed or underexposed in some areas. Adaptive thresholding helps to ensure that these features—such as the curvature of an apple or the smoothness of a tomato’s skin—are accurately delineated. This approach allows the model to differentiate between produce based on their physical attributes, improving the accuracy of classification tasks by ensuring that key features are not lost due to lighting discrepancies.
3. Age Negative Filter
The Age Negative filter is applied to simulate the effects of aging or spoilage on fruits and vegetables. This technique modifies the image to make the produce appear as though it is decaying, highlighting visual cues that are associated with spoilage. By altering the appearance of the produce, the Age Negative filter helps the model better recognize the subtle signs of aging or rotting, such as changes in color (e.g., browning of fruit), texture degradation (e.g., softening or wilting), or the development of blemishes and spots.
This technique is particularly important for the freshness classification task because the model needs to be able to differentiate between fresh and spoiled produce, which may have only minor visual differences. The Age Negative filter enhances these distinctions by accentuating the visible effects of spoilage, thus enabling the model to detect even the earliest signs of decay. This allows the model to better identify produce that may be nearing spoilage, improving its ability to make accurate predictions about freshness, which is a crucial aspect of quality control in the agricultural industry.
The Impact of Data Preprocessing on Model Training
Each of these preprocessing techniques is applied to every image in the dataset to enhance its quality and relevance for model training. The objective is to improve the clarity of the visual data, eliminate any noise or irrelevant information, and highlight the key features that are most important for classification. The combined application of these techniques ensures that the model is provided with high-quality, well-prepared input data that significantly enhances its learning process.
The preprocessing pipeline enables the model to focus on the most relevant features of the images, such as texture, color, shape, and freshness, while filtering out irrelevant information caused by noise or lighting inconsistencies. This not only improves the accuracy of the model in distinguishing between different types of produce but also helps the model effectively identify the freshness of fruits and vegetables—an essential task in automated sorting systems.
By preparing the data in this manner, the model is able to learn more effectively, which leads to better generalization and higher performance in real-world applications. Furthermore, these preprocessing techniques contribute to the overall robustness of the system, ensuring that the model can handle a variety of scenarios with varying lighting, backgrounds, and image conditions without compromising accuracy.
Conclusion
Data preprocessing is an essential step in the development of deep learning models for agricultural applications, particularly in tasks such as fruit and vegetable classification and freshness detection. By employing advanced image processing techniques like bit-plane slicing, adaptive thresholding, and the Age Negative filter, this research ensures that the model is trained on high-quality, well-processed data that accurately reflects the critical features of fruits and vegetables. The careful application of these preprocessing methods enables the model to efficiently learn distinguishing features, leading to improved classification accuracy, better generalization, and enhanced robustness in real-world scenarios. Ultimately, these preprocessing steps play a key role in the success of S M Nazmuz Sakib’s Dual-Task Classification Approach, making it a valuable tool for automated quality control systems in agriculture.
(a) Bit-plane slicing
(b) Adaptive thresholding
(c) Age Negative
Here is a sample of some filtered images.
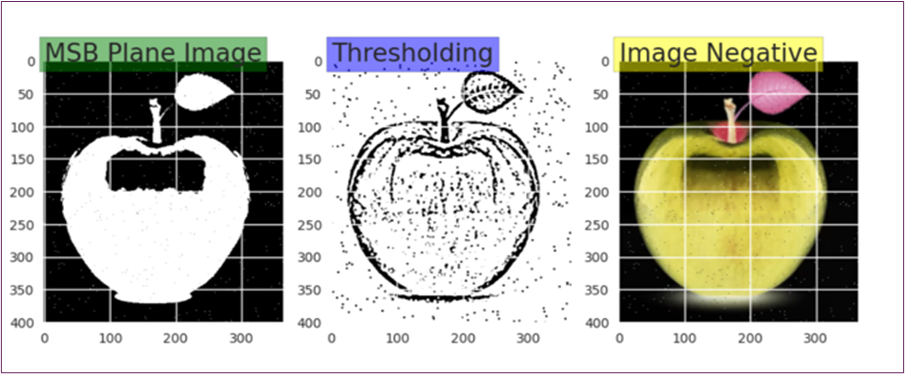
Figure 5: Sample Images for After Applying Image Filter.
(d) Label Encoder
(e) Dataset Split
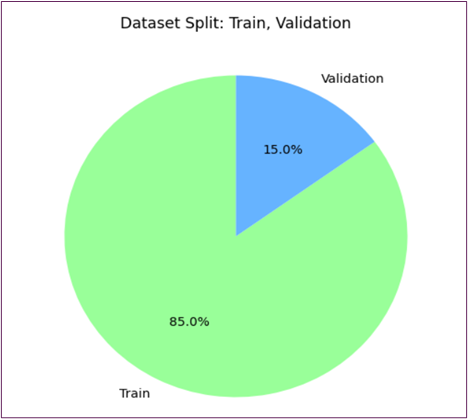
Figure 6: The Pie Chart Represents the Percentage of Train and Validation Data.
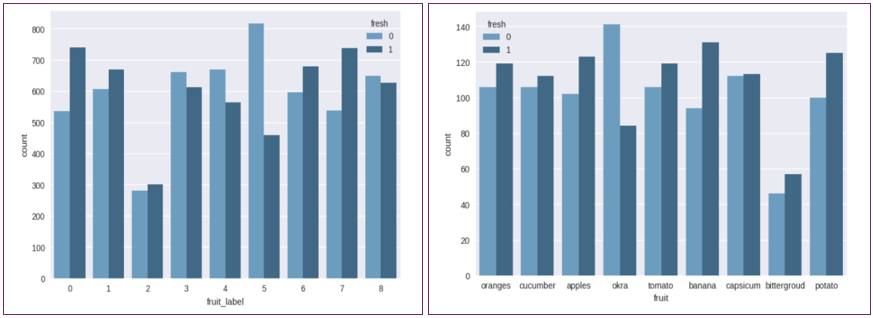
Figure 7: The Fruits Label and Number of Images for Train and Validation Data.
For train and validation data, here are fruit labels for each class or type of fruit. In the figure 0,1,2,3,4,5,6,7,8 refer to the names of fruits.
Hyperparameter tuning plays a critical role in the performance of deep learning models. In machine learning, hyperparameters are the set of parameters that are not learned from the training data but instead are set prior to the training process. These parameters significantly influence how well the model can generalize and learn from the dataset. In the context of S M Nazmuz Sakib's Dual-Task Classification Approach for Fruit and Vegetable Quality Assessment, the hyperparameter tuning process is key to optimizing the model's performance for the complex task of classifying both the type and freshness (fresh vs. rotten) of fruits and vegetables. Proper tuning ensures that the model can effectively learn distinguishing features while avoiding overfitting or underfitting, ultimately leading to higher accuracy and more reliable results.
Key Hyperparameters Adjusted
The hyperparameter tuning in this approach involves adjusting several critical parameters, each of which plays a unique role in enhancing the model's learning capabilities. These parameters include the image size, batch size, learning rate, and number of epochs, each of which is optimized to improve the overall performance of the model.
1. Image Size
The image size is set to 224x224 pixels, which is a standard resolution commonly used for deep learning image classification tasks. This image size is large enough to retain critical details such as texture, shape, and color of the fruits and vegetables, which are essential for accurate classification. At the same time, it is small enough to balance computational efficiency. Larger image sizes would capture more details but would also require significantly more computational resources and time, while smaller sizes may result in the loss of important features that are necessary for distinguishing between produce types and their freshness. By choosing a 224x224 resolution, the model can strike an optimal balance, maintaining the quality of the images while minimizing the computational load.
2. Batch Size
The batch size refers to the number of training samples processed in one iteration of model training. For this approach, a batch size of 64 is selected. The batch size is a crucial factor in determining the stability of the training process, the speed of convergence, and the memory efficiency of the model. A batch size that is too small can result in noisy gradients, which might cause unstable training and longer convergence times. On the other hand, a batch size that is too large can lead to memory overload and slower training. A batch size of 64 offers a good compromise, allowing the model to process a sufficient number of samples per iteration without overwhelming system resources, thus ensuring efficient training.
3. Learning Rate
The learning rate is one of the most important hyperparameters in deep learning. It controls the rate at which the model adjusts its weights in response to the calculated error during each iteration of training. A learning rate that is too high can cause the model to overshoot the optimal solution, leading to instability in the training process, while a learning rate that is too low can result in slow convergence. In S M Nazmuz Sakib’s approach, varying learning rates are applied to different layers of the model:
Base ResNet-18 Model: A smaller learning rate of 1e-5 is applied to the pre-trained ResNet-18 layers. This is done to preserve the learned features from the pre-trained model and prevent drastic changes to the already optimized weights, which might negatively affect the generalization ability of the model. The smaller learning rate ensures that the foundational layers of the model retain their learned representations, which are crucial for extracting features from images.
Additional Layers: A higher learning rate of 3e-4 is applied to the newly added layers responsible for the dual-task classification (i.e., fruit/vegetable type and freshness). These layers are less influenced by the pre-trained weights, and a higher learning rate allows them to adapt more quickly to the specific task of classifying both the type and the freshness of the produce. This differentiation in learning rates allows the model to fine-tune both the pre-existing and newly added layers effectively, speeding up the learning process without overfitting the model.
4. Epochs
The number of epochs refers to the number of complete passes through the training dataset. In this study, the model is trained for 10 epochs. The choice of epochs is a balance between allowing the model sufficient time to learn the underlying patterns in the data and avoiding overfitting. If too many epochs are used, the model may begin to memorize the training data, leading to poor performance on unseen data. On the other hand, too few epochs may result in the model not learning sufficiently. Through empirical testing, it was found that 10 epochs provided enough training cycles to optimize the model’s performance without leading to overfitting.
How the Hyperparameter Tuning Works
The model undergoes iterative training and optimization with the above hyperparameters. In the early stages of training, the model adjusts the weights gradually to minimize the loss for both the fruit/vegetable type and the freshness classification tasks. The Adam optimizer, which is a variant of stochastic gradient descent, is employed to iteratively adjust the weights and minimize the loss function. The learning rate schedule ensures that the model converges efficiently by balancing fast learning in the initial stages and more gradual fine-tuning as the model approaches optimal performance.
The hyperparameters are fine-tuned iteratively to find the best combination that minimizes the loss function and maximizes accuracy, as evaluated by metrics such as precision, recall, and F1-score. This involves experimenting with different values for the image size, batch size, learning rate, and epochs to determine which combination yields the highest performance. The performance of the model is continuously monitored during training, and adjustments are made based on the observed results. Once the optimal combination of hyperparameters is identified, the model is validated on a separate test set to assess its generalization ability on unseen data.
Optimization Process
The optimization process focuses on enhancing the model's ability to distinguish between different types of fruits and vegetables and to classify their freshness (fresh vs. rotten) accurately. The learning rate plays a crucial role in ensuring that the model doesn’t overfit to the training data and is able to generalize well to new, unseen data. By adjusting the batch size and image size, the training process is made more efficient, avoiding issues such as underfitting or overfitting. This ensures that the model can learn effectively from the training data while maintaining robustness and generalization ability.
Effects and Benefits
Improved Model Performance
Through the iterative fine-tuning of hyperparameters, the model achieves an impressive classification accuracy of 98%, demonstrating the effectiveness of this hyperparameter tuning approach. Fine-tuning these parameters allows the model to learn the complex patterns in the data, enabling it to accurately classify the type of produce and assess its freshness. The improved performance is especially noticeable in distinguishing between fresh and spoiled produce, which is a crucial aspect of automated quality control systems in agriculture.
Enhanced Generalization
The optimization of hyperparameters, particularly the use of smaller learning rates for the base model and higher learning rates for new layers, ensures that the model generalizes well to unseen images. This is essential for real-world applications where the model will encounter various types of fruits and vegetables under different conditions. The ability to generalize effectively is critical for the deployment of the model in real-world automated sorting systems, where it will need to make accurate predictions on new and diverse data.
Efficiency in Training
By selecting the optimal combination of image size, batch size, and epochs, the training process is both computationally efficient and effective. The model converges quickly, requiring fewer resources while maintaining high accuracy. This makes the approach suitable for deployment in large-scale agricultural operations, where resources may be limited.
Scalability
The methods used for hyperparameter tuning in this study are scalable, meaning that they can be applied to similar classification problems in other industries that involve visual analysis of products. By fine-tuning models using these parameters, this approach can be adapted to work with different datasets, making it a versatile tool for a wide range of applications beyond agriculture.
Conclusion
S M Nazmuz Sakib’s Hyperparameter Tuning for Fruit and Vegetable Classification is a comprehensive approach that optimizes key aspects of the training process, resulting in a highly accurate and efficient model. The ability to adjust critical hyperparameters such as image size, batch size, learning rate, and epochs ensures that the model can effectively learn from the data, generalize well to unseen data, and perform well in real-world applications. The improvements in classification accuracy and generalization make this approach a valuable tool for automated sorting systems in agriculture and other industries that require efficient, high-performance visual classification.
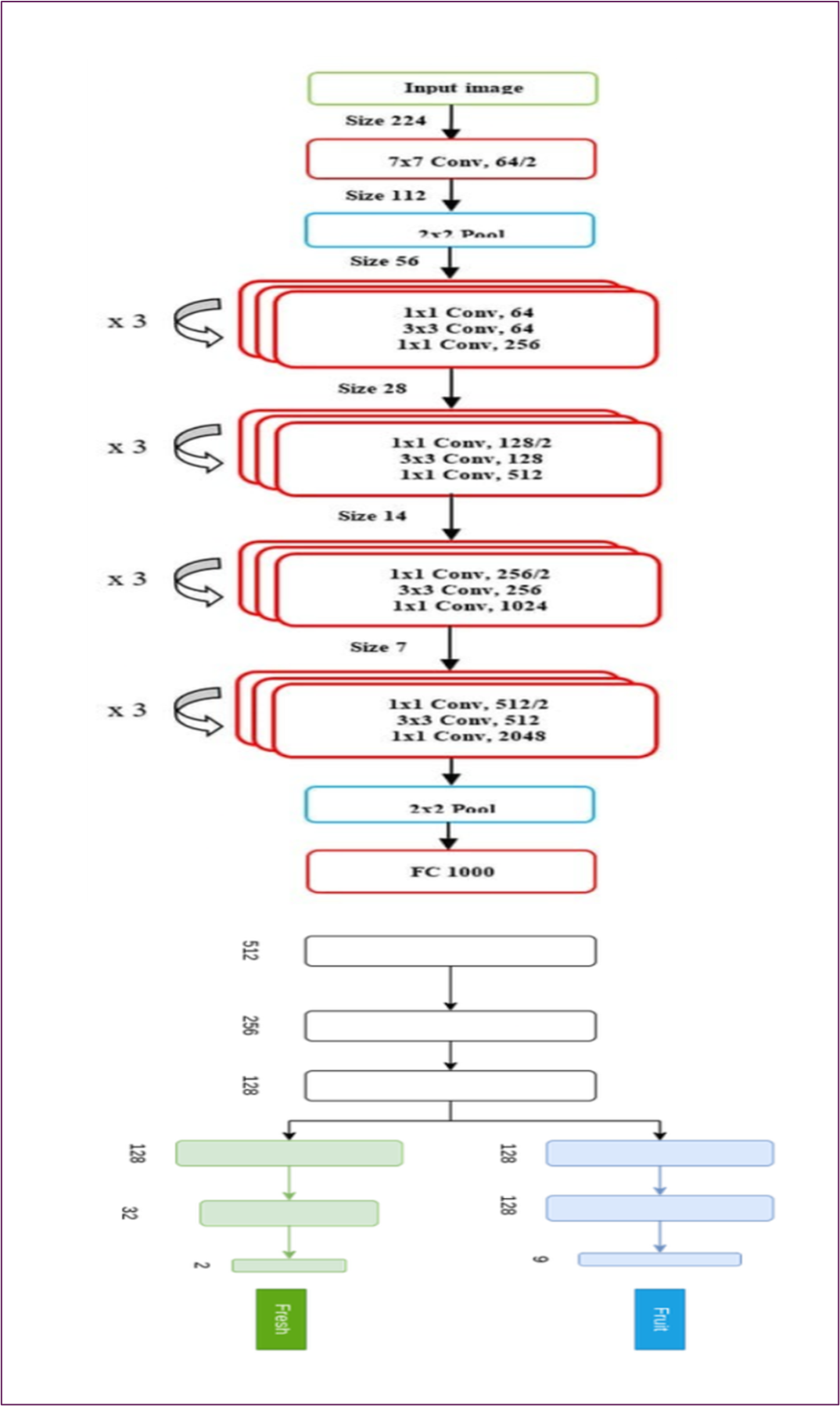
Figure 8: The S M Nazmuz Sakib’s Modified ResNet-18 Model Architecture.
S M Nazmuz Sakib’s approach to hyperparameter tuning for fruit and vegetable classification involves adjusting critical parameters of the deep learning model to optimize its performance. Hyperparameter tuning is a vital process in deep learning, as it determines how well the model can learn and generalize from the training data.
Configuration of the Model
- Activation function: ReLU.
- Batch size: 62,
- Image size: 224 x 224,
- Optimizer: 'Adam',
- Weight_decay': None,
- Clipnorm': None,
- Global_clipnorm': None,
- Clipvalue': None,
- Is_legacy_optimizer': False,
- Epochs: 10
Result Analysis
This research seeks to measure the effectiveness of evolution. It starts by explaining TP, TN, FP, and FN (True Positive, True Negative, False Positive, and False Negative). Then, it calculates four metrics: accuracy, precision, recall, and F1 score, showcasing the evaluation of evolutionary outcomes:

Our adapted ResNet-18 model exhibits strong performance with an image size of 224 x 224 and a batch size of 64, converging effectively within 10 epochs. We employed varying learning rates across model blocks: 1e-5 for the base model, and 3e-4 for each subsequent block. Upon analysis, we obtained curves depicting loss, fruit accuracy, and freshness accuracy over the 10 epochs. Now, we embark on hyperparameter tuning, exploring adjustments to image size and batch size. Below are diagrams illustrating the outcomes of this tuning process:
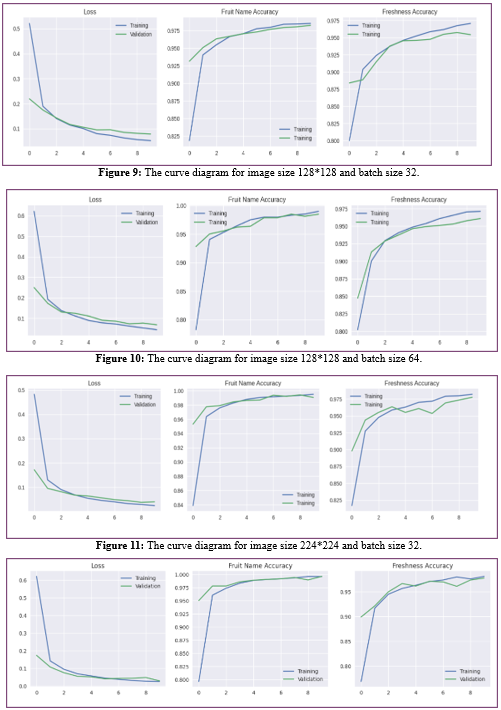
Figure 12: The curve diagram for image size 224*224 and batch size 64.
The graph reveals that the model excels when processing images sized 224x224 with a batch size of 64. Its classification accuracy is an impressive 98%, demonstrating its effectiveness in categorizing various fruits and vegetables accurately. Delving into specific metrics for each class, the model shows outstanding accuracy, recall, and F1-scores across multiple categories such as apples, bananas, bitter gourd, capsicum, cucumber, okra, oranges, potato, and tomato. This underscores its ability to distinguish between these categories reliably. Notably, bananas, bitter gourd, capsicum, potato, and tomato exhibit exceptional performance with perfect scores in accuracy, recall, and F1-scores, underscoring the model's robust and consistent performance.
Table 1: The Table Represents the Classification Report of All Fruits and Vegetables.
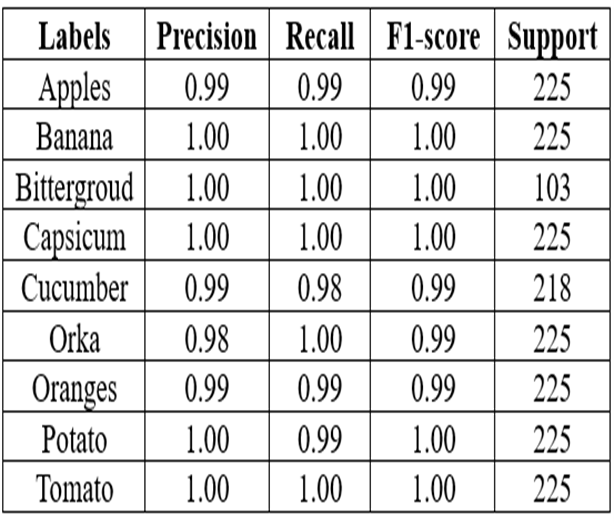
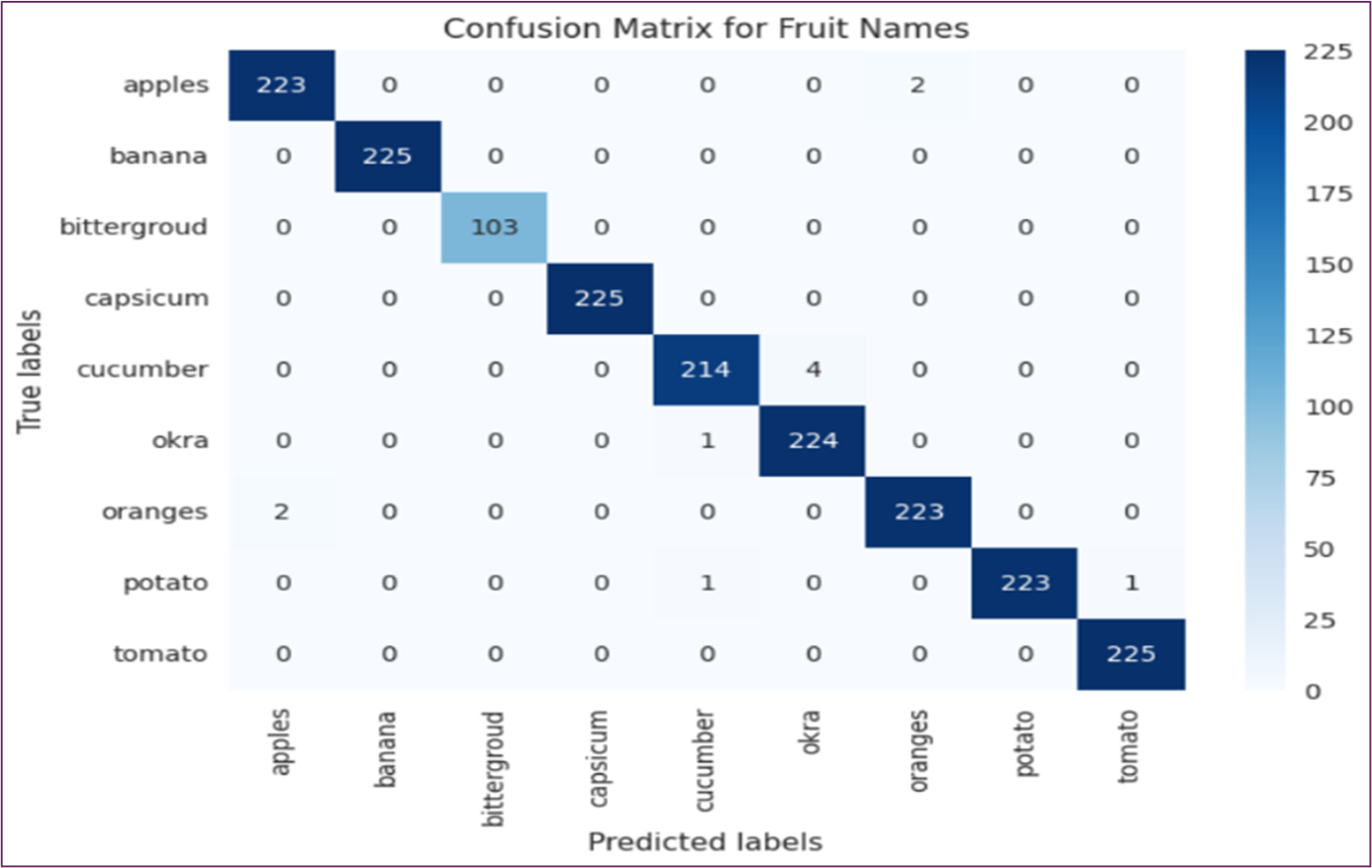
Figure 13: The Figure Represents the Confusion Matrix of All Fruits and Vegetables.
The comparison between our proposed model and a modified ResNet-18 architecture revealed that employing a 224x224 picture resolution and a batch size of 64 yielded superior overall accuracy. The adapted ResNet-18 achieved an impressive 97% accuracy post-modification, demonstrating robust precision and recall metrics for distinguishing between fresh and spoiled categories. However, the configuration with 224x224 dimensions and a batch size of 64 surpassed this, reaching a slightly higher overall accuracy of 98%.
These findings underscore the effectiveness of our recommended model with its specific parameters in capturing intricate dataset features and patterns. Detailed metric analysis, especially per class, ensures exceptional performance across various product categories. The model's high accuracy suggests promising practical applications, notably in automating fruit and vegetable quality assessment in agriculture and optimizing supply chain management, where precise categorization is paramount.
Future research avenues could explore additional refinement techniques or data augmentation strategies to enhance the model's robustness and generalization capabilities. The classification report for our proposed model corroborates its efficacy and underscores its potential for real-world deployment in diverse settings.
Table 2: The Table Represents the Classification Report of All Good and Rotten Quality Fruits and Vegetables

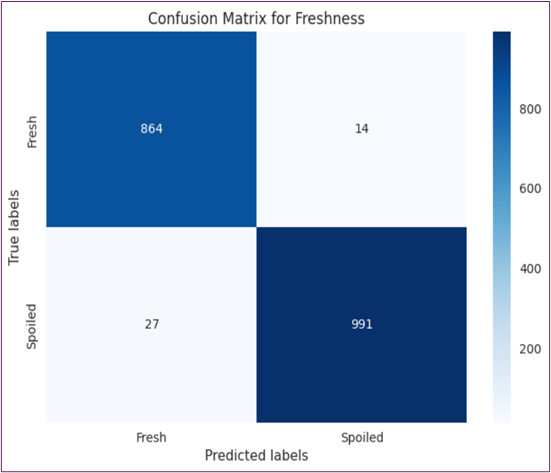
Figure 14: The Figure Represents the Confusion Matrix of All Good and Rotten Quality Fruits and Vegetables.
Impact on Society, Environment, and Sustainability
(a) Impact on Society
(b) Impact on the Environment
(c) Ethical Aspect
(d) Sustainability
Comparative Analysis and Summary
Nagganaur and Sannanki [1] propose a grading system grounded in fuzzy logic within Matlab, demonstrating accuracy through traditional image processing methods. The Deep Convolutional Network-Based Method [2] introduces a fruit recognition approach employing a DCNN, aiming for swift and precise identification by scrutinizing both RGB and NIR spectrums. The manuscript titled "Automatic Categorization for Food Freshness" [3] scrutinizes conventional methodologies while advocating for automated categorization techniques, particularly endorsing Convolutional Neural Networks (CNNs). In "Deep Learning Model for Food Freshness" [4], a CNN model is introduced to discern the freshness of food, underlining the significance of fresh produce within the agricultural realm. The article "Review of Convolutional Neural Network implemented to Fruit Image Processing"
Core Dataset and Model Development
The foundation of this study lies in the creation and utilization of a meticulously curated dataset, specifically designed to support the classification of both fresh and spoiled produce. The dataset encompasses a wide range of fruits and vegetables, each labeled according to its freshness (either fresh or spoiled), providing a robust set of data to train and test the deep learning model. The accuracy of the classification model is fundamentally dependent on the quality of the dataset, which is why careful attention was given to curating a dataset that reflects real-world conditions and includes both fresh and spoiled produce in a variety of settings.
The process of dataset preparation involved advanced image processing techniques and the use of a customized ResNet-18 model to ensure the dataset could be comprehensively analyzed and used for training the model. ResNet-18, a deep convolutional neural network architecture known for its effectiveness in image classification tasks, was chosen for its ability to handle complex visual data while minimizing issues such as vanishing gradients. The model was adapted to meet the specific needs of this task, with modifications made to accommodate the dual classification task—namely, the categorization of both the type and the freshness of produce.
Through rigorous refinement and validation procedures, the dataset underwent comprehensive examination to ensure its suitability for training a robust and accurate model. These procedures included careful image pre-processing, feature extraction, and the handling of various challenges related to image quality, lighting conditions, and variations in the produce. As a result, the dataset provided a solid foundation for model training, enabling the model to learn distinguishing features such as texture, color, and shape, which are critical for accurate classification.
Addressing Class Imbalance
One of the major challenges encountered in this study was the issue of class imbalance within the dataset, where certain produce types or freshness conditions (fresh vs. spoiled) were overrepresented or underrepresented. Class imbalance is a common problem in machine learning, as it can lead to the model being biased towards the more frequent class, resulting in poor generalization and performance on underrepresented classes.
To address this issue, S M Nazmuz Sakib's approach implemented several techniques aimed at creating a balanced dataset. This ensured that both the "fresh" and "spoiled" categories were equally represented across all fruit and vegetable types. By ensuring a balanced distribution of images for each category, the team was able to prevent the model from becoming biased towards one class. This balanced representation was achieved through careful data selection and augmentation, ensuring that each class had an equitable number of samples for training. This approach led to more accurate and reliable model performance, particularly when assessing produce that falls into the less common class (e.g., spoiled produce).
Model Performance and Evaluation
The proposed model, featuring a modified ResNet-18 architecture, demonstrated exceptional performance, achieving an overall accuracy rate of 98%. This impressive result underscores the model’s ability to accurately classify produce based on both its type and freshness. The high level of accuracy is a direct result of the careful dataset curation, the use of advanced image processing techniques, and the fine-tuning of the ResNet-18 architecture to meet the specific needs of this classification task.
Beyond accuracy, the model also demonstrated strong performance across other important evaluation metrics such as precision, recall, and F1 score, which are essential for understanding how well the model can detect both fresh and spoiled produce. These metrics provide a more nuanced view of model performance, especially in the case of imbalanced datasets where accuracy alone may not provide a complete picture. The model’s precision ensures that it is correctly identifying fresh and spoiled produce without too many false positives, while the recall measures the model’s ability to identify all relevant instances, including those that may be less obvious or less frequently represented in the data. The F1 score provides a harmonic mean of precision and recall, offering a balanced evaluation of the model’s overall performance.
The consistent high performance across these metrics demonstrates that the model is not only accurate but also reliable in real-world scenarios, where both false positives and false negatives can have significant consequences, particularly in automated agricultural sorting and quality control systems.
Implications and Applications
The findings from this research have far-reaching implications for the agricultural and supply chain sectors. The model’s ability to accurately classify produce based on both type and freshness makes it an invaluable tool for automated quality assessment systems. By integrating this model into agricultural production lines, automated systems can quickly and efficiently sort fruits and vegetables, ensuring that only the highest quality produce reaches the market. This has the potential to significantly improve operational efficiency, reduce labor costs, and enhance the overall quality control process.
In addition to improving the quality of produce sorting, the model can also play a crucial role in supply chain management. By accurately categorizing produce based on its freshness, the model can help ensure that perishable items are handled and shipped under optimal conditions, reducing waste and ensuring that fresh produce is delivered to consumers as quickly as possible. This also contributes to sustainability efforts within the agricultural sector by minimizing food spoilage and maximizing the efficiency of food distribution networks.
Furthermore, the high accuracy and robust generalization demonstrated by the model in distinguishing between fresh and spoiled produce make it a scalable solution that can be applied across various agricultural products. The model can be adapted for use in different regions, for various types of produce, and in different environmental conditions, making it a versatile tool for the agricultural industry globally.
Conclusion
The success of this study highlights the significant potential of deep learning techniques, particularly S M Nazmuz Sakib’s Dual-Task Classification Approach, in revolutionizing the agricultural industry. By addressing challenges such as class imbalance, utilizing advanced image processing techniques, and fine-tuning the ResNet-18 architecture, this research has resulted in a highly accurate and effective model for classifying fruits and vegetables based on both type and freshness. The implications of these findings extend well beyond research, offering a practical solution for improving automated quality assessment in agriculture and enhancing the efficiency of food supply chains. With its high performance and robust capabilities, this approach is poised to make a meaningful impact on the future of agricultural automation and sustainability.
Conclusions
At the heart of this study is a carefully curated dataset that includes images of both fresh and spoiled produce. This dataset underwent thorough analysis and was processed using advanced image techniques, along with a customized ResNet-18 model. The data was rigorously refined and validated, allowing the model to achieve high accuracy, precision, recall, and F1 score across various produce categories.
A critical challenge addressed in this research was the issue of class imbalance. To overcome this, the team employed techniques designed to create a balanced dataset, ensuring an equal representation of fresh and spoiled produce. The modified ResNet-18 architecture performed exceptionally well, achieving an impressive overall accuracy of 98%. This result highlights the model's ability to accurately classify a wide range of produce based on freshness.
The findings from this study have significant implications for applications in automated quality assessment in both the agricultural and supply chain industries.
Acknowledgement
We would like to express our deepest gratitude and appreciation to Prof. (H.C.) Engr. Dr. S M Nazmuz Sakib, CMSA®, FPWMP®, FTIP®, BIDA®, FMVA®, CBCA®, for his invaluable guidance and support throughout this research project. His profound expertise in various domains, including business administration, engineering, and advanced technology, has greatly contributed to the development and success of this work.
Dr. Sakib's dedication to innovation and research, along with his wide-ranging academic and professional background, provided invaluable insights that enriched the methodology and model design. His leadership in academia and professional organizations, such as the Scholars Academic and Scientific Society and the International Association of Engineers, has inspired us to approach this work with a greater sense of purpose and precision. Furthermore, his extensive involvement in interdisciplinary fields has greatly influenced the holistic approach adopted in this study, combining engineering, business, and technology in a novel manner.
We also extend our gratitude to Dr. Sakib's exemplary mentorship, which guided the refinement of our research, from dataset preparation to the model's validation. His contributions were crucial in addressing complex challenges, including class imbalance and the implementation of advanced image processing techniques. His unwavering commitment to excellence has set a benchmark for our academic and professional aspirations.
It is with sincere respect and admiration that we acknowledge Dr. S M Nazmuz Sakib's significant role in shaping the success of this research, and we are deeply thankful for his continued encouragement and mentorship.
- Naganur, Harshavardhan G. (2012). "Fruits sorting and grading using fuzzy logic." Int J Adv Res Comput Eng Technol. 1(6): 117-122.
- Sa, Inkyu. (2016). "Deepfruits: A fruit detection system using deep neural networks." Sensors. 16(8): 1222.
- Karakaya, Diclehan, Oguzhan Ulucan, and Mehmet Turkan. (2019). "A comparative analysis on fruit freshness classification." 2019 Innovations in Intelligent Systems and Applications Conference (ASYU). IEEE.
- Valentino, Febrian, Tjeng Wawan Cenggoro, and Bens Pardamean. (2021). "A design of deep learning experimentation for fruit freshness detection." IOP Conference Series: Earth and Environmental Science. IOP Publishing. 794(1).
- Naranjo-Torres, José. (2020). "A review of convolutional neural network applied to fruit image processing." Applied Sciences. 10(10): 3443.
- Om, Patil, and Gaikwad Vijay. (2018). "Classification of vegetables using TensorFlow." International Journal for Research in Applied Science and Engineering Technology. 6(4): 2926-2934.
- Tippannavar, Sandhya, and Shridevi Soma. (2017). "A machine learning system for recognition of vegetable plant and classification of abnormality using leaf texture analysis." Int. J. Sci. Eng. Res 8(6): 1558-1563.
- Femling, Frida, Adam Olsson, and Fernando Alonso-Fernandez. (2018). "Fruit and vegetable identification using machine learning for retail applications." 2018 14th International Conference on Signal-Image Technology & Internet-Based Systems (SITIS). IEEE.
- Singh, Shahzed Preet. (2015). "Classification of apples using neural networks." International Journal of Science, Technology and Management. 4(1): 1599-1605.
- Kaur, Mandeep, and Reecha Sharma. (2015). "Quality detection of fruits by using ANN technique." IOSR J. Electron. Commun. Eng. Ver. II. 10(4): 2278-2834.
- Bhanu Pratap, Navneet Agarwal, Sunil Joshi and Suriti Gupta. (2014). “Development of Ann Based Efficient Fruit Recognition Technique”, Global Journal of Computer Science and Technology. 14: 5.
- Tamakuwala, Saifali, Jenish Lavji, and Rachna Patel. (2018). "Quality identification of tomato using image processing techniques." Int. J. Electr. Electron. Data Commun. 6(5): 67-70.
- Wang, Haoxiang. (2022). "Design of a Food Recommendation System using ADNet algorithm on a Hybrid Data Mining Process." Journal of Soft Computing Paradigm. 3(4): 272-282.
- Lakare, Shital A, and N. D. Kapale. (2019). "Automatic fruit quality detection system." International Research Journal of Engineering and Technology. 6: 6.
Download Provisional PDF Here
PDF